1. 索引
1.1. 聚集索引与回表
1.1.1. 聚集索引 (clustered index)
聚集索引(clustered)也称聚簇索引,这种索引中,数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。 一个表的物理顺序只有一种情况,因此对应的聚集索引只能有一个。如果某索引不是聚集索引, 则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
自增主键和uuid作为主键的区别么?由于主键使用了聚集索引,如果主键是自增id, 那么对应的数据一定也是相邻地存放在磁盘上的,写入性能比较高。 如果是uuid的形式,频繁的插入会使innodb频繁地移动磁盘块,写入性能就比较低了。
- 如果表定义了主键,则Primary Key 就是聚集索引;
- 如果表没有定义主键,则第一个非空唯一索引(Not NULL Unique)列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
1.1.2. 普通索引(secondary index)
普通索引也叫二级索引,除聚簇索引外的索引都是普通索引,即非聚簇索引。 不同于聚集索引,非聚集索引叶子节点上不再是真实数据,而是存储了索引字段自身值和主键索引。 使用聚集索引查询可以直接定位到记录,而普通索引通常需要扫描两遍索引树(第一次普通索引,第二次聚集索引), 即先通过普通索引定位到主键值,在通过聚集索引定位到行记录,这就是所谓的回表查询,它的性能比扫描一遍索引树低。
- InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
1.1.3. 回表
回表或者二次查询:使用聚集索引查询可以直接定位到记录, 而普通索引通常需要扫描两遍索引树,即先通过普通索引定位到主键值, 在通过聚集索引定位到行记录,这就是所谓的回表查询,它的性能比扫描一遍索引树低
1.2. 组合索引
- https://zhuanlan.zhihu.com/p/346849749
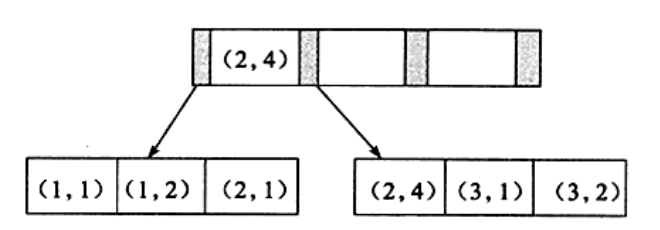
1.2.1. 等值最左前缀匹配
- 1、全值匹配查询时(where子句搜索条件顺序调换不影响索引使用,因为查询优化器会自动优化查询顺序 ),可以用到联合索引
- 2、匹配左边的列时,可以用到联合索引
- 3、未从最左列开始时,无法用到联合索引
- 4、查询列不连续时,无法使用联合索引(会用到a列索引,但c排序依赖于b,所以会先通过a列的索引筛选出a=1的记录, 再在这些记录中遍历筛选c=3的值,是一种不完全使用索引的情况)
1.2.2. 范围最左前缀匹配
- 1 范围查询最左列,可以使用联合索引
- 2 精确匹配最左列并范围匹配其右一列(a值确定时,b是有序的,因此可以使用联合索引)
- 3 精确匹配最左列并范围匹配非右一列(a值确定时,c排序依赖b,因此无法使用联合索引, 但会使用a列索引筛选出a>2的记录行,再在这些行中条件 c >3逐条过滤)
1.3. 索引失效
- 条件字段原因
- <>、NOT、in、not exists
- 查询条件中使用OR
- 查询条件使用LIKE通配符 SQL语句中,使用后置通配符会走索引, 例如查询姓张的学生(SELECT * FROM student WHERE name LIKE ‘张%’),
而前置通配符(SELECT * FROM student WHERE name LIKE ‘%东’)会导致索引失效而进行全表扫描。 - 索引列上做操作(计算,函数,(自动或者手动)类型装换)
- 索引列数据类型不匹配 SELECT * FROM student WHERE age=’18‘索引失效,因为age是整形
- 索引列使用IS NOT NULL或者IS NULL可能会导致无法使用索引
2. explain
EXPLAIN 是 MySQL 中用于分析查询执行计划的命令。当你对一个 SQL 查询使用 EXPLAIN 时,MySQL 会返回查询的执行计划,而不是执行查询本身。这可以帮助你了解查询是如何被 MySQL 优化的,以及查询的性能瓶颈在哪里。
使用 EXPLAIN 可以帮助你:
- 确定查询是否使用了索引:如果查询没有使用索引,那么它可能会非常慢,尤其是当数据量很大时。
- 查看查询的类型:例如,是
ALL(全表扫描)、index(全索引扫描)还是range(范围扫描)等。 - 查看哪些列被使用:这可以帮助你确定是否所有的列都被正确地使用了。
- 确定哪些索引被使用:这可以帮助你了解是否应该为特定的列添加索引。
- 检查查询的行数:
EXPLAIN会估计为了执行查询需要扫描的行数,这可以帮助你预测查询的性能。 - 检查可能的额外开销:例如,
Using filesort或Using temporary表明查询可能需要额外的排序或临时表,这可能会降低性能。
如何使用 EXPLAIN:
假设你有一个名为 users 的表,并且你想查询年龄大于 25 的所有用户:
EXPLAIN
SELECT *
FROM users
WHERE age > 25;
执行上述查询后,你会得到一个结果集,其中包含了关于查询执行计划的详细信息。
常见的 EXPLAIN 输出列:
- id: 查询的标识符。
- select_type: 查询的类型(例如 SIMPLE, SUBQUERY, DERIVED 等)。
- table: 输出的表名。
- type: 访问类型(例如 ALL, index, range, ref, eq_ref, const, system, NULL)。https://www.cnblogs.com/xxoome/p/14434061.html
- possible_keys: 可能使用的索引。
- key: 实际使用的索引。
- key_len: 使用的索引的长度。
- ref: 哪些列或常量被用作索引查找的参考。
- rows: 估计需要检查的行数。
- Extra: 额外的信息,如 “Using where”, “Using index”, “Using temporary”, “Using filesort” 等。
为了获得最佳的性能,你应该经常使用 EXPLAIN 来检查你的查询,并根据其建议进行优化。
3. InnoDB和MyISAM的区别
InnoDB和MyISAM是MySQL数据库管理系统中最常用的两种存储引擎,它们在处理数据库事务、锁定机制、存储方式等方面有一些显著的区别。
- 事务处理:InnoDB支持事务处理,具有ACID特性,提供了更好的数据完整性和并发性能。 而MyISAM不支持事务处理,这意味着它无法提供数据的原子性、一致性、隔离性和持久性保证。
- 锁定机制:InnoDB支持行级锁定,这可以提高并发访问的性能,因为它允许多个事务同时访问不同的数据行。 而MyISAM只支持表级锁定,当对一个表进行操作时,会锁定整个表,这可能会降低并发性能。
- 存储方式:InnoDB将数据存储在磁盘上的InnoDB表空间数据文件中,表的大小只受限于操作系统文件的大小。 而MyISAM将数据存储在三个文件中,包括表定义文件(.frm)、数据文件(.MYD)和索引文件(.MYI)。
- 外键支持:InnoDB支持外键约束,这有助于维护数据的引用完整性。而MyISAM则不支持外键。
- 性能:在某些情况下,MyISAM的性能可能会比InnoDB更好,尤其是在执行大量的SELECT查询时。 这是因为MyISAM的表强调的是性能,其执行速度比InnoDB更快。然而,在需要执行大量的INSERT、UPDATE或DELETE操作时, InnoDB通常表现更好,因为它支持事务处理和行级锁定。
综上所述,InnoDB和MyISAM各有其优点和适用场景。在选择存储引擎时,应根据具体的应用需求和性能要求来决定使用哪种引擎。
4. 查询优化
4.1. 使用索引:
- 确保查询中用于筛选、排序和分组的字段都有索引。
- 避免在索引列上使用函数或运算,这会导致索引失效。
- 考虑使用复合索引来优化多列的查询条件。
- 定期分析表和索引的使用情况,使用EXPLAIN命令查看查询的执行计划。
4.2. 优化查询语句:
- 避免在查询中使用SELECT *,只选择需要的列。
- 使用JOIN代替子查询,当可能时。
- 避免在WHERE子句中使用OR,使用UNION代替。
- 使用LIMIT来限制返回的结果集大小。
- 避免在WHERE子句中使用非确定性的函数。
- 使用小表去驱动大表
4.3. 分表分库
对于非常大的表,考虑使用分区来提高查询性能。
5. 索引
在 MySQL 中,索引是用于快速查找数据库表中数据的数据结构。索引的创建可以显著提高查询性能,因为它允许数据库系统避免全表扫描,而是直接定位到满足查询条件的数据行。以下是 MySQL 中索引的基本概念和工作原理:
5.1. 索引类型
-
B-Tree 索引:
- 最常用的索引类型,用于 InnoDB 和 MyISAM 存储引擎。
- 支持全值匹配、最左前缀匹配、范围查询和排序操作。
- B-Tree 索引适用于大多数查询类型。
-
哈希索引:
- 适用于等值查询,不支持范围查询。
- MySQL 的 MEMORY 存储引擎支持哈希索引。
-
空间索引 (R-Tree):
- 用于地理空间数据类型,如 GEOMETRY。
- 支持空间查询操作。
-
全文索引:
- 用于文本搜索,如
MATCH() ... AGAINST()查询。 - MyISAM 和 InnoDB 存储引擎支持全文索引。
- 用于文本搜索,如
-
聚簇索引:
- InnoDB 存储引擎的主键索引就是聚簇索引。
- 数据行实际上存储在索引的叶子节点中,因此主键查询非常快。
-
非聚簇索引:
- 非主键索引都是非聚簇索引。
- 非聚簇索引的叶子节点包含指向数据行的指针。
5.2. 索引工作原理
-
B-Tree 索引工作原理:
- B-Tree 是一种平衡的多路搜索树。
- 索引的每一层节点(除了叶子节点)都保存了指向子节点的指针。
- 查找时,从根节点开始,根据查找值在节点中进行二分查找,找到符合条件的子节点指针,然后递归查找,直到找到叶子节点或找不到为止。
- 插入和删除操作也会维护 B-Tree 的平衡。
-
哈希索引工作原理:
- 哈希索引使用哈希函数将键值转换为存储位置。
- 查找时,使用同样的哈希函数计算键值的哈希值,然后直接定位到存储位置。
- 由于哈希函数的特点,哈希索引不支持范围查询。
-
全文索引和空间索引:
- 这两种索引类型使用特定的算法和数据结构来处理文本和空间数据。
- 全文索引使用倒排索引技术,将文本中的每个单词映射到一个包含该单词的文档列表。
- 空间索引使用 R-Tree 数据结构来存储空间对象的几何形状。
5.3. 索引优化建议
-
选择性高的列:
- 选择性是指不重复值与总行数之间的比率。
- 高选择性的列(如唯一键或主键)更适合创建索引。
-
避免过度索引:
- 每个索引都会占用存储空间,并增加写操作的开销。
- 只对经常用于查询条件的列创建索引。
-
考虑查询优化:
- 使用
EXPLAIN命令分析查询的执行计划。 - 根据执行计划调整索引或查询语句。
- 使用
-
定期维护:
- 使用
OPTIMIZE TABLE命令定期优化表,以减少索引碎片。
- 使用