1. 背景
某业务线的同学要发布一个新的查询接口,需要进行压力测试, 以核定发布时需要的机器资源
2. 分析过程
2.1. 压测过程
在使用50线程,持续300秒的情况下,压测一分钟后,ApacheJMeter进程宕机了。 在使用50线程,持续120秒的情况下,压测二分钟后,正常结束。 在使用50线程,持续180秒的情况下,压测一分钟后,ApacheJMeter进程宕机了。
2.2. 定位过程
通过调整压测的时长,只得出了时间一长就宕机的结果, 导致宕机原因是什么没有定位到,限定在以下几个方面
- 1 入参的数据有问题,如NULL,或是其他导致异常的入参
- 2 jvm的垃圾回收配置不适合当前的场景
- 3 内存不足
2.2.1. 猜想1
检查了数据,没有NULL,或空串
2.2.2. 猜想2
使用的G1垃圾回收,压测过程中,GC也是存在的。直到压测到某个时间点。jstat -gc 返回的数据不再变化。(已经宕机) 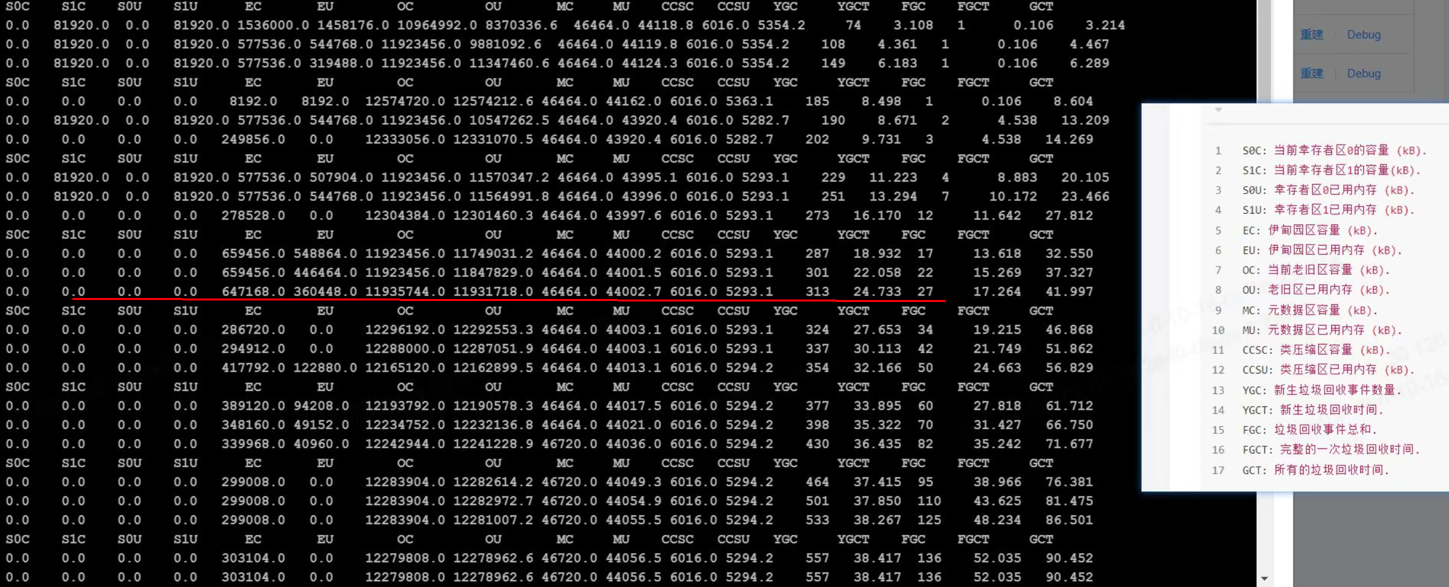
2.2.3. 猜想3
把8核16G的机器,升级到32G。程序正常运行。使用jstat -gc 实时观测也发现内存需要20G左右。 后来发现每次返回的报文,保存为txt文件在180+KB。 峰会的QPS在1200左右。也就是一秒的返回数据就在210.93MB。一分钟 就会有210M*60=12.30G的数据,但这里最原始的报文数据, 中间还要入参、转存、序列化等过程,都需要内存开销,开始的16G, 不够用。所以在某个线程执行时,返回了OutOfMemory的异常。 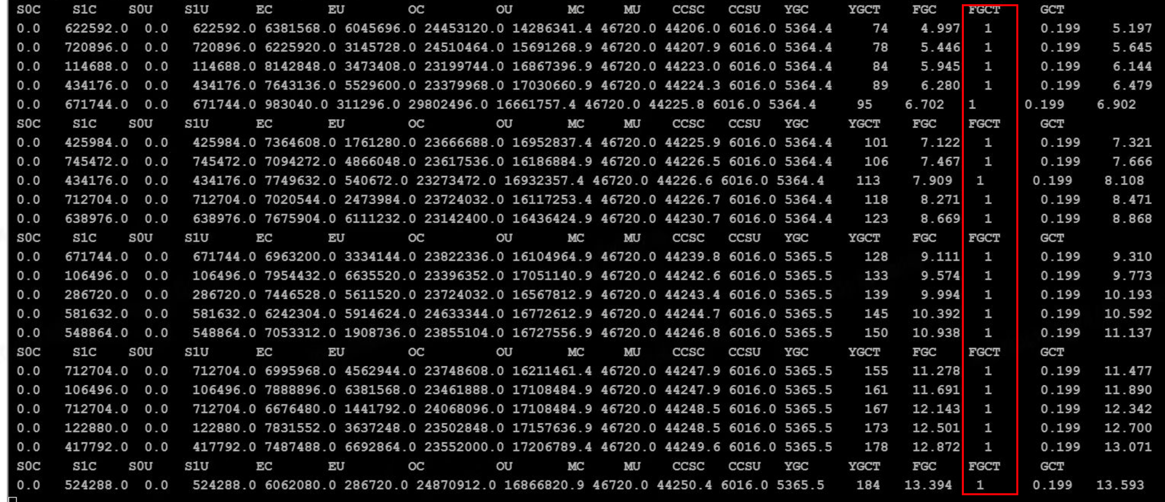
2.3. 思考
对于这种返回数据巨大的数据,可以通过提高FGC的次数,来兼容这种因为单次数据巨大而引发总量过大, 最终OutOfMemory的问题吗?
通过猜想2的图片,应该是不行的,猜想2 FGC一直都在进行, 猜想3因为内存足够,所以FGC次数没有增加。